









私はSeleniumを使って、とあるフリマサイトの自動操作ツールを作成しています。
ツールでは商品画像のURLを取得して、ローカルPC側にダウンロードしている部分があるのですが、最近、画像が取得できなくなってしまいました。
その原因と対応について自分用にメモします。
1. エラー内容
「static.mercdn.net」というサイトで画像が保存されています。
Seleninumで画像URLを取得 → urllibで直接画像をダウンロードしているのですが、エラー内容としては以下の403エラーが表示されました
urllib.error.HTTPError: HTTP Error 403: Forbidden2. 原因
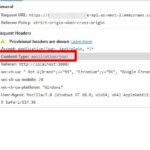
調査したところ、直接Chromeなどのブラウザではアクセスができるのですが、urllib経由でアクセスするとエラーになります。
原因としては、相手サーバ側でUserAgentで判別してurllib経由でのアクセスをエラーにしているようです。
3. 対応
と、いう事でurllibでアクセスする際にUserAgentを偽装することで対応します。
具体的には以下のように記載を変更します。今回はChromeのUserAgentにします。
【変更前】
img_name = self.get_save_img_name(img_url)
save_img_path = self.conf.path_image_dir + img_name
with urllib.request.urlopen(img_url) as web_file:
data = web_file.read()
with open(save_img_path, mode='wb') as local_file:
local_file.write(data)【変更後】
UserAgentを偽装するための関数を追加しているだけです。
img_name = self.get_save_img_name(img_url)
save_img_path = self.conf.path_image_dir + img_name
req = self.request_as_chrome(img_url)
with urllib.request.urlopen(req) as web_file:
data = web_file.read()
with open(save_img_path, mode='wb') as local_file:
local_file.write(data)
# 関数追加
def request_as_chrome(url):
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"}
return urllib.request.Request(url,None,headers)これでアクセスすると問題なく画像を取得できるようになりました。
今回は以上となります。
コメント