




Seleniumを使ってスクレイピングをするスクリプトをAWS lambda上で動作させる際にハマったのでメモします。
ちなみにLambdaのPythonバージョンが3.9だと以下の方法を実施してもSeleniumは動作しないようです。Seleniumの実行エラーになります。
Python3.7にすると動作するようになりましたのでご注意ください。
1. 前提
- 開発環境としてWindows10にPythonをインストールしている
- Lambda関数はPython3.7で作成
2. SeleniumをLambdaで実行する方法
Lambdaをそのままアップして利用してもLambda上の標準ライブラリにSeleniumは入っていないのでエラーになります。
[ERROR] Runtime.ImportModuleError: Unable to import module 'lambda_function': No module named 'selenium'アップロードするlambadフォルダ内に含んでもよいのですが、ChromeDriverとHeadless-chromiumだけでもLambdaのデプロイサイズ上限である50MBになってしまうので、今回はLambda Layersを利用したいと思います。
3. AWS Lambda Layersの作成
3.1. AWS Lambda Layersとは?
AWS Lambda Layers とはlamda から共通的に使える共通関数のようなもので、ライブラリのような共通で使用するモジュールをLayerにすることで、デプロイパッケージにライブラリを含める必要がなくなります。
Lambdaでサードパーティ製のライブラリやモジュールを使用する際に、Layerに格納して各Lambda関数から呼び出して使用するというような使い方ができます。
3.2. SeleniumのLambda Layers作成
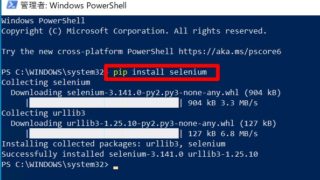
pipコマンドでSeleniumを任意のディレクトリにダウンロードしてからzip化します。
> pip install -t ./python/lib/python3.7/site-packages selenium
> zip -r ./python python.zip3.3. Headless-chromiumのLambda Layers作成
以下のサイトからそれぞれダウンロードしていきます。
ダウンロードするのはLinux版です。念のため。
Chromdriver:
https://chromedriver.chromium.org/downloads
headless-chromium
https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip
ダウンロードしたファイルに実行権をつける必要があります。
Windowsの場合にはできないので一旦Linuxにファイルを移動してからパーミッションを変更してください。
<<Linux上で実施>>
# chmod 755 chromedriver
# chmod 755 headless-chronium
# zip chromedriver.zip chromedriver headless-chronium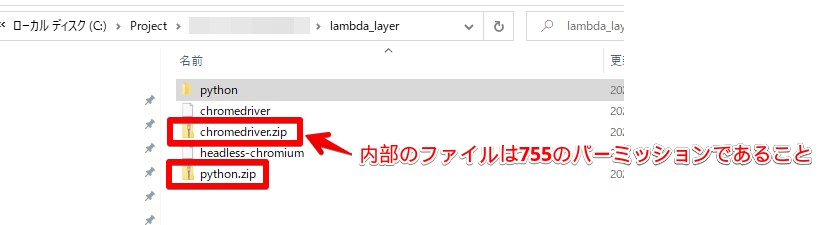
4. AWS Lambda Layersへのアップロード
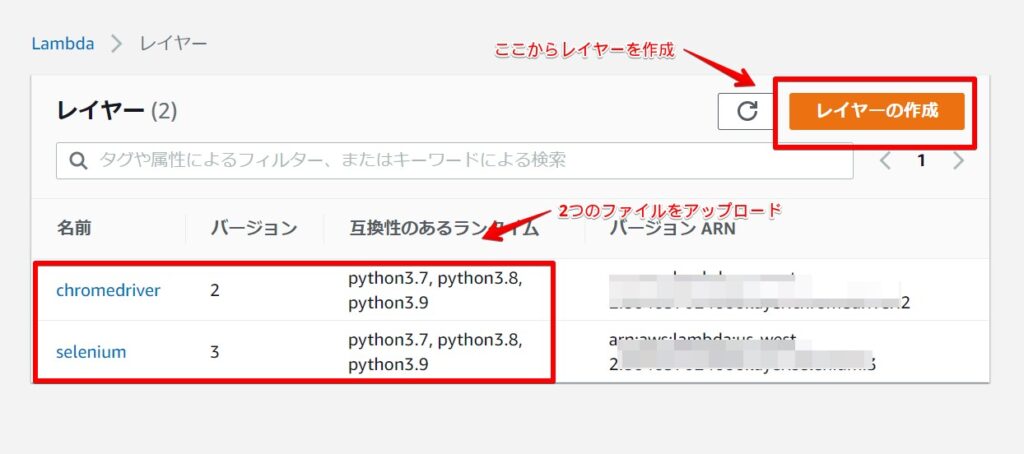
作成した2つのzipファイルを順にLambda Laypersとしてアップしていきます。
最終的に以下のようになります(バージョンは違ってもOKです)
5. Lambda関数に Lambda Layersを追加する
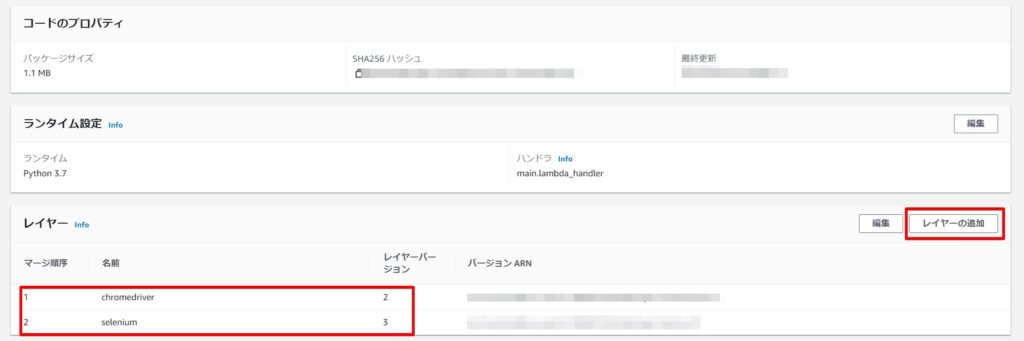
実際に利用しているLambda関数側で先ほど作成したLambda Layersを利用するように設定します。
6. ChromeDriverの呼び出しパス(executable_path)の指定
Lambda側の準備はできましたので、最後にスクリプト側の修正を行います。
AWS Lambda layersは読み込んだ際に、「/opt」 に配置されるようになりますのでChromedriverを下記のように指定します。
options.binary_location = '/opt/headless-chromium'
driver = webdriver.Chrome(executable_path ="/opt/chromedriver", chrome_options=optionsちなみに私は以下のように実行する環境がローカル(Windows)かLambda(Linux)かで読み込む内容を自動的に変更するようにしました。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--single-process')
options.add_argument('--disable-dev-shm-usage')
if os.name == 'nt':
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
else:
options.binary_location = '/opt/headless-chromium'
driver = webdriver.Chrome(executable_path="/opt/chromedriver", chrome_options=options)7. タイムアウト値の変更
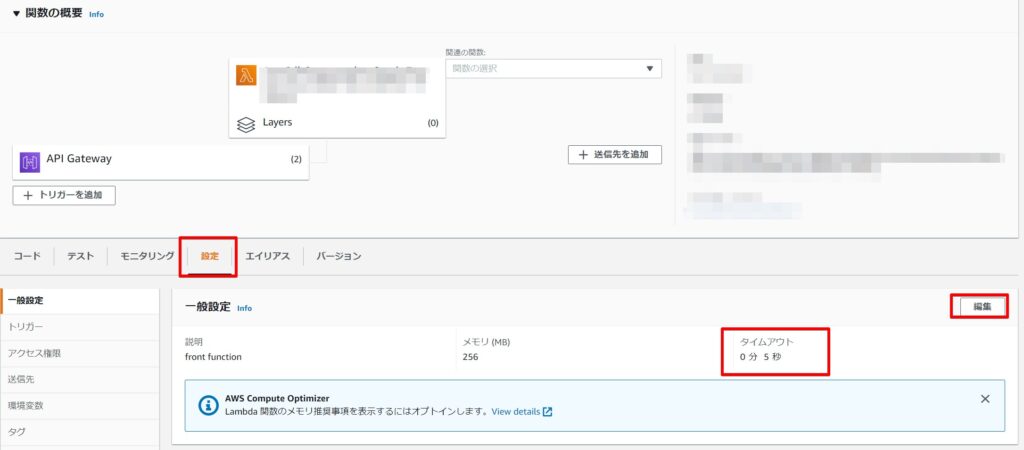
初期作成時のLambdaのタイムアウトは5秒です。
スクレイピングには時間がかかるのでタイムアウト値も変更しましょう。
8. まとめ
今回はSeleniumをAWS Lambda上で動作させる際の手順についてまとめました。
PC上ではなくて、Lambda上で実施できるのはかなりメリットがありますね。
Pythonのオススメ勉強方法
私がオススメするPython初心者向けの最初に購入すべき書籍は「シリコンバレー一流プログラマーが教える Pythonプロフェッショナル大全」です。
シリコンバレー一流プログラマーが教える Pythonプロフェッショナル大全

この書籍は実際にシリコンバレーの一流エンジニアとして活躍している酒井潤さんが書いた本です。
内容も初心者から上級者までまとめられており、各Lessonも長すぎずに分かりやすくまとめられているので、初心者の方にもおすすめです。
シリコンバレー一流プログラマーが教える Pythonプロフェッショナル大全
今回は以上となります。


コメント