






前回はQuickSightの申し込みまでを行いました。
https://syachiku.net/amazon-quicksight01/
今回は実際のデータを見える化するために必要なAmazon S3の準備を行っていきます。
1. S3バケットの作成
まず、見える化するデータを保存するためのバケットとフォルダを作成します。
今回は「quicksight-gogolon-test」という名前で作成して、その下にフォルダを作成します。
2. サンプルデータの作成スクリプトを準備
既にデータがある場合には不要ですが、サンプルデータを作成するためのスクリプトを作成します。
日時とランダム数字、あとはランダム数字に応じてHigh、Lowを判断するくらいのスクリプトを作成します。
主な仕様としては以下です。
- 0~10の範囲でのランダム数字を取得、5以上ならHigh、4以下ならLowを記録
- 実行時間とランダム数字、HighかLowの結果をCSVファイルに記載
- 1秒に1回実施
- 1分単位でファイル(datas/%Y%m%d_%H%M.csvに追記
スクリプトはこんな感じです。
import csv
import time
import random
from datetime import datetime
def quicksight_sample():
while True:
random_number = random.randint(0, 10)
CSV_FILE = "datas/"+datetime.now().strftime('%Y%m%d_%H%M')+".csv"
result = "Low"
if random_number >= 5:
result = "High"
print(datetime.now().strftime('%Y-%m-%d %H:%M:%S')+","+str(random_number)+","+result)
data = [datetime.now().strftime('%Y-%m-%d %H:%M:%S'), random_number,result]
with open(CSV_FILE, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(data)
time.sleep(1)
if __name__ == '__main__':
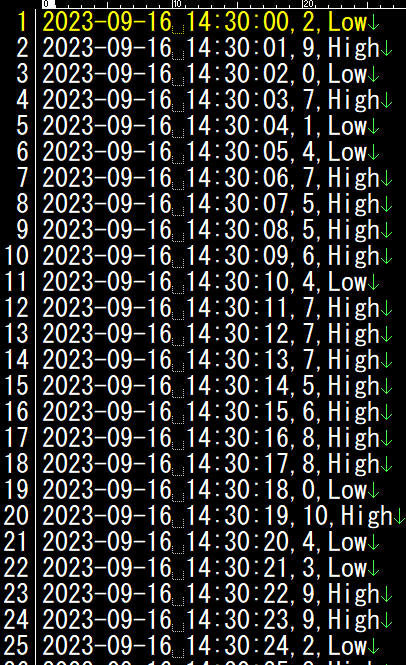
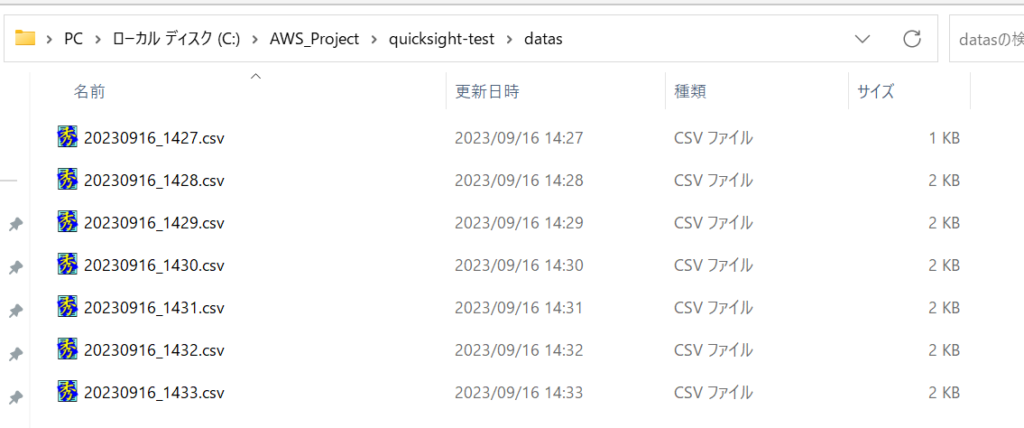
quicksight_sample()結果としてはこんな感じで1分単位でのファイルを蓄積されていきます。
今回は以上となります。
コメント