






現在、WindowsでPython+Selenium+ChromeDriverでRPAツールを作成しています。
自動ブラウザ操作の仕組みを「Python+Selenium+ChromeDriver」(長いのでこの後からSeleniumとします)で作っているのですが、ログオン認証が必要なサイトへアクセスする際には、毎回ログオンページが表示されてしまいます。
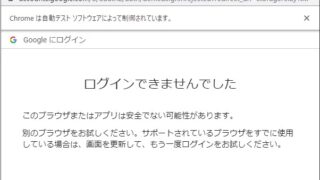
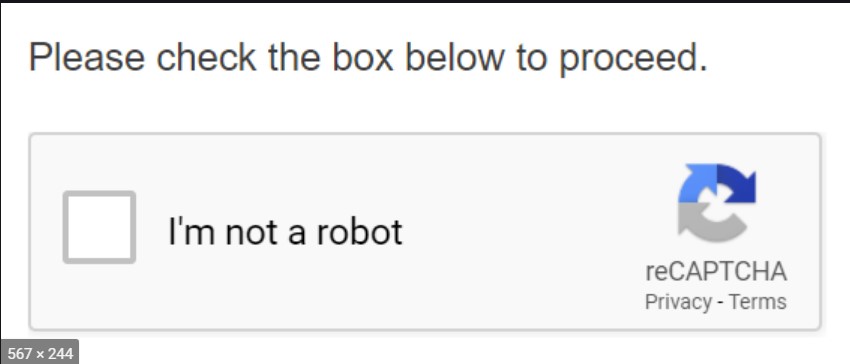
入力フォームだけのサイトであれば、毎回Selenium経由でフォームに自動的にパラメータを投入すれば問題ないのですが、以下のようなCAPCHAを使っている場合に対応はかなり難しくなります。

そこで、今回はCAPCHAのログオン認証があった場合の対応(回避)方法について記載いたします。
Seleniumで毎回ログオンが聞かれる理由
普通にユーザがChromeを利用していると初回はログオン認証を行いますが、2回目以降はログオン認証することなくそのままログオンした状態でアクセスができるようになるかと思います。
これは「ユーザプロファイル」というアクセス時に利用するユーザ情報を使ってアクセスしているためです。
ただし、今回のようなSeleniumを使ってのアクセスでは「ユーザプロファイル」を毎回リセットした状態でアクセスしているため毎回ログオン認証が必要になるということです。
対応方法
では、本題の対応方法についてですが、Seleniumでアクセスするときもこの「ユーザプロファイル」を持った状態でアクセスすればよいのです。
やり方は簡単です。Chromeを立ち上げる際のオプションに「user-data-dir」を付けて、ユーザプロファイルのフォルダを指定します。
例としてこのブログの編集画面を開くようにして試してみます。
import time
from selenium import webdriver
import chromedriver_binary
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# ログオンURL
url = "https://syachiku.net/wp-admin/edit.php"
# ユーザプロファイルのフォルダ名(実行フォルダに作成されます)
user_profile = 'UserProfile'
# Optionでユーザプロファイルの場所を指定する
options = webdriver.ChromeOptions()
options.add_argument('--user-data-dir=' + user_profile)
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(30)
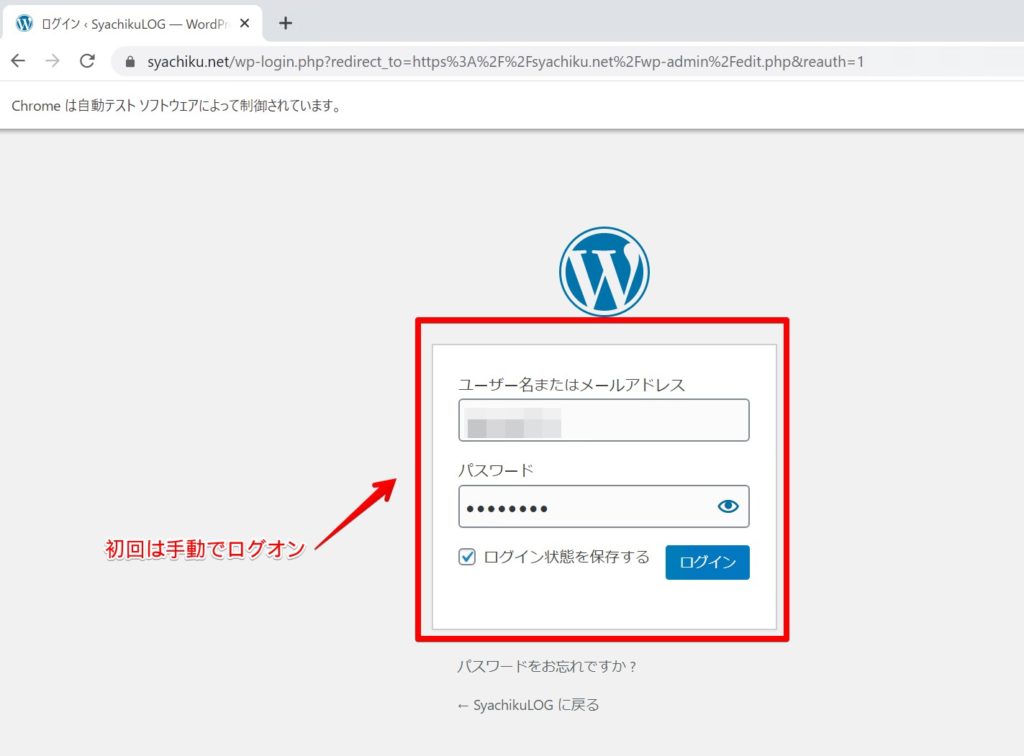
driver.close()まず、スクリプトを実行すると最初は認証が必要なため、ログオン画面が開きます。手動でログオン情報を入力してみてください。
2回目を実行してみます。
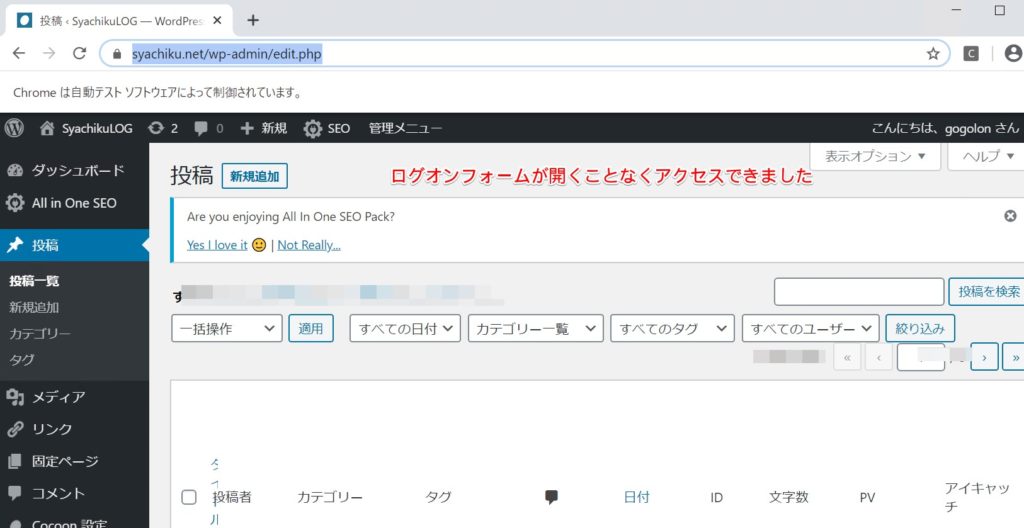
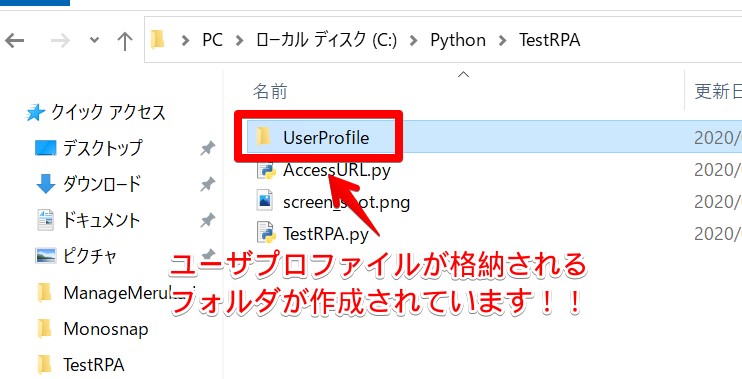
ここで追加している「user-data-dir」で指定しているものは、「プロファイル(のパス)」です。プロファイルにはcookieやら履歴、ブラウザの設定情報などが含まれています。
既にChromeをインストールしている場合は、以下の手順で確認出来ます。
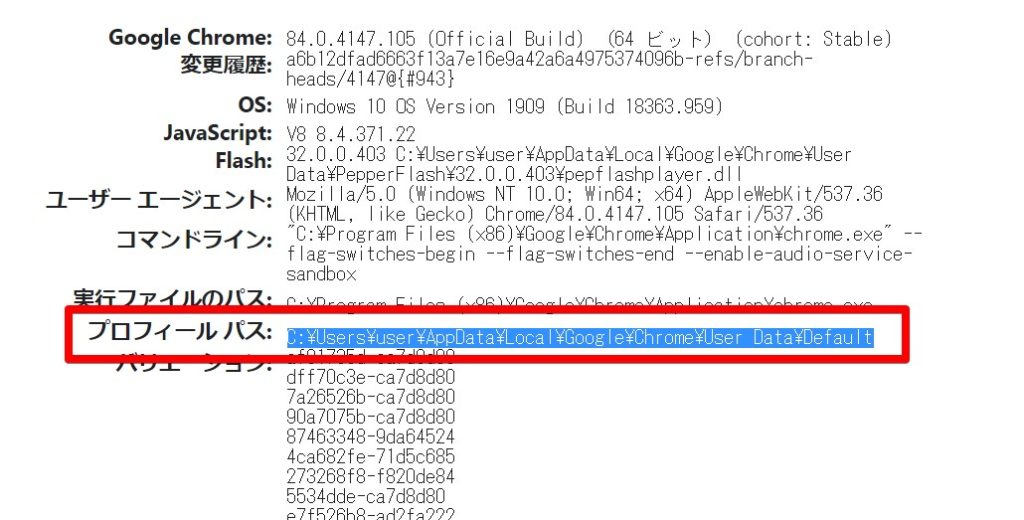
①Chromeを起動する
②アドレスバーに「chrome://version」と入力してエンターを押す
そうするとプロフィールパスに現在のユーザーの保管フォルダが表示されます、これをスクリプト内で利用するようにしてください。
まとめ
今回はCAPTAなどを利用している認証サイトに対してあらかじめ「ユーザプロファイル」の情報を保管しておいて、それを流用することでログオン処理を解決する方法について紹介しました。
これで少しずつRPAツールに必要な要素が整ってきました。
しかし、Seleniumはほぼ100%でブラウザ操作がシミュレートできるのでかなり有用だと感じました。
以前に利用していたUWSCよりも使い勝手がよい気がします。
Pythonのオススメ勉強方法
私がオススメするPython初心者向けの最初に購入すべき書籍は「シリコンバレー一流プログラマーが教える Pythonプロフェッショナル大全」です。
シリコンバレー一流プログラマーが教える Pythonプロフェッショナル大全

この書籍は実際にシリコンバレーの一流エンジニアとして活躍している酒井潤さんが書いた本です。
内容も初心者から上級者までまとめられており、各Lessonも長すぎずに分かりやすくまとめられているので、初心者の方にもおすすめです。
シリコンバレー一流プログラマーが教える Pythonプロフェッショナル大全
今回は以上となります。


コメント